构建基于向量数据库与知识图谱的高效RAG系统 数据处理的关键步骤
随着人工智能技术的快速发展,检索增强生成(Retrieval-Augmented Generation,RAG)系统在自然语言处理领域展现出巨大潜力。RAG系统结合了检索和生成模型的优势,能够从大规模知识库中提取相关信息,并生成准确、连贯的文本响应。而向量数据库和知识图谱作为两种核心的数据管理技术,为构建高效RAG系统提供了强有力的支撑。本文将探讨如何通过数据处理流程,整合向量数据库和知识图谱,以实现RAG系统的高效运行。
数据处理是RAG系统构建的基础。数据来源多样化,包括结构化数据(如数据库表格)、半结构化数据(如JSON文件)和非结构化数据(如文本、图像、音频)。数据处理的第一步是数据清洗与预处理,包括去除噪声、标准化格式、处理缺失值等。对于非结构化文本数据,还需进行分词、词性标注、实体识别等自然语言处理操作,以提取关键信息。这一步骤的质量直接影响后续检索和生成的准确性。
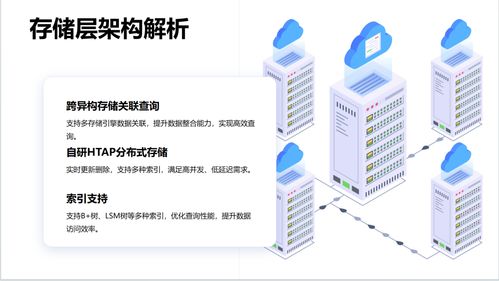
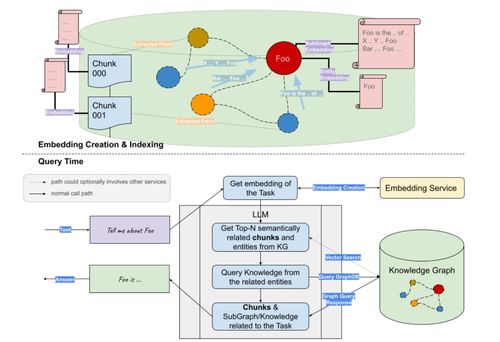
向量数据库在RAG系统中扮演着关键角色。向量数据库专门用于存储和管理高维向量数据,这些向量通常由文本嵌入模型(如BERT或Sentence-BERT)生成。在数据处理过程中,原始文本通过嵌入模型转换为向量表示,这些向量捕捉了文本的语义信息。向量数据库支持高效的相似性检索,使得RAG系统能够快速找到与查询最相关的文档片段。例如,当用户提出一个问题时,系统会将查询转换为向量,并在向量数据库中搜索最接近的向量,从而检索出相关信息。数据处理在此阶段需确保向量的质量和一致性,避免语义漂移或噪声干扰。
知识图谱则提供了结构化的知识表示方式。它由实体、属性和关系组成,能够显式地表达领域知识。在数据处理中,构建知识图谱涉及实体抽取、关系抽取和知识融合等步骤。实体抽取从文本中识别出关键对象(如人物、地点),关系抽取则建立这些对象之间的连接(如“出生于”)。知识图谱的引入增强了RAG系统的推理能力,因为它允许系统利用逻辑关系进行更复杂的检索。例如,在回答“爱因斯坦的出生地是什么?”时,知识图谱可以直接提供“爱因斯坦-出生于-乌尔姆”这样的三元组,而不是依赖纯文本匹配。数据处理需确保知识图谱的准确性和完整性,避免错误传播。
将向量数据库与知识图谱结合,可以构建更强大的RAG系统。一种常见的方法是在数据处理中实现双路检索:一方面使用向量数据库进行语义相似性检索,另一方面利用知识图谱进行关系型检索。例如,系统可以先通过向量检索获取相关文档,再通过知识图谱验证和丰富这些信息。数据处理流程需要协调这两种技术,确保数据的一致性和实时性。增量更新是数据处理的重要环节,随着新数据的加入,系统需动态更新向量索引和知识图谱,以保持RAG系统的时效性。
高效的数据处理离不开优化策略。在向量数据库方面,可以采用近似最近邻搜索算法(如HNSW)来平衡检索速度和精度;在知识图谱方面,图数据库(如Neo4j)能够支持高效的关系查询。数据处理应注重可扩展性,以应对大规模数据流。监控和评估也是关键,通过指标如检索准确率、响应时间等,持续优化数据处理流程。
向量数据库和知识图谱的结合为RAG系统提供了强大的数据支撑。通过精细的数据处理,包括清洗、向量化、图谱构建和集成检索,我们可以实现高效、准确的生成式应用。随着多模态数据和实时处理需求的增长,数据处理技术将进一步演进,推动RAG系统在智能客服、知识管理等领域发挥更大作用。
如若转载,请注明出处:http://www.hanzhengroom.com/product/13.html
更新时间:2025-11-28 22:04:57